
This paper proposes a model of researcher-AI interaction and argues that ethnographers can smartly leverage AI in data analysis if they deepen their understanding of AI tools. The growing use of artificial intelligence (AI)-enabled research tools in qualitative research has generated new and novel ways for researchers to interact with AI in data analysis, such as through the application of natural language processing (NLP) and machine learning (ML) algorithms on qualitative datasets. With the advancement of AI technologies, and its sensationalization within broader culture, sociotechnical entanglements have become increasingly complex, asking ever more of ethnographers, pushing their understandings of what constitutes the analytic process and the insights derived. It is critical for ethnographers to recognize the relationship inherent in interactions with AI-enabled research tools and develop a flexible approach to conceptualizing the researcher’s role within these relationships given the fast-paced changes AI will likely bring to how ethnographers approach analyzing data. Scant interrogation has been placed specifically on AI-enabled qualitative data analysis and the relationship created between researcher and algorithm. This researcher-AI relationship is a relatively unknown territory and is deserving of greater explication.
BACKGROUND
Asking each other questions to validate our own thoughts and experiences, to hear similar stories, or to gasp at tales that conflict with our understanding of the world are inherently human activities. Social science disciplines exist because of the curiosities we have about each other and the human need to understand how we are similar or different. In part because of this desire for inquiry, an experience that most of us are accustomed to in today’s world is taking a survey. We encounter surveys most often through email links – near daily invitations to provide feedback about the companies we work for or shop from, the colleges we attend, or restaurants and other services we may interact with often. A survey can be an easy task, albeit slightly boring, most frequently done in the privacy of one’s own thoughts and with no interaction between other participants or a moderator. Now, imagine a type of survey that is more conversational where you find yourself in a virtual ‘room’ at the same time as up to 1,000 participants, interacting with their responses and stating your level of agreement or disagreement to their answers, while a moderator guides the conversation with planned questions and spur-of-the-moment probes. Combining both qualitative and quantitative question types, many hybrid AI-enabled research tools like the type described have proliferated in recent years, and have become more commonly used in qualitative research. One such tool is Remesh, a research platform that leverages AI algorithms to help understand research participants thoughts, feelings, and perceptions. An algorithm, for the purposes of this paper, is best understood as akin to a recipe – the Remesh platform uses multiple algorithms (or recipes) to analyze data.
The Remesh platform lends a new experience to participant and researcher alike, opening a traditional focus group to scale (up to 1,000 participants) and bringing the nuance of qualitative data to a traditional survey. Although Remesh is a fully text-based platform, participating in a Remesh ‘conversation’ is unlike a survey in that participants interact with each other’s responses and are able to view some question results in real time. Facilitating the process – and what makes this artificial intelligence (AI)-enabled tool unique – are preference-inference machine learning (ML) and natural language processing (NLP) algorithms working in concert to analyze participant response data in real time. During these conversations, participants are not only interacting with other participants, but also the moderator and fellow researchers, conversation observers, the platform interface, the preference-inference ML and NLP algorithms and the algorithms’ engineering makers and maintainers. In a Remesh conversation all who contribute – whether participant, researcher, observer, or engineer – become a contained community, linked across time/space, connected by platform interface and algorithm, each an actor in a network that invites curiosity and debate.
This collaboration is awash in the mundane activities of any research endeavor (discussion guide creation, sample recruitment, client management, etc.) with the added layers of preference-inference ML and NLP algorithms, and the excitement of live data collection with co-occurring analysis. Despite the recent sensationalism the field of AI has attracted (especially generative and facial recognition capabilities), Remesh’s preference-inference ML algorithm’s main purpose is to assign agreement scores to each participant response. A typical output might look like this:
I really like breakfast foods, but not the images of foods I see here. 68%
No chance of AI hallucinations or biased facial recognition here – the preference-inference algorithm scores each response based on actual participant voting behavior (described in detail later). The lack of sensationalism, however, belies the friction between the work of an ethnographer in producing analytic results and the work of an algorithm in producing analytic results. Is one or the other’s work more valid? Is faster or slower work more important, better, or more accurate? As ethnographers continue to adopt AI-enabled tools to answer questions about culture and people, what responsibilities do ethnographers have in acknowledging the work of algorithms, and do algorithms’ engineering makers and maintainers have a responsibility to acknowledge the work of ethnographers?
This paper explores the ethnographer-AI relationship in data analysis and proposes a networked understanding of this relationship as a path to unlocking answers about analytic work, validity and responsibility.
LITERATURE REVIEW
The popularity of AI software currently available in the US market has increased in tandem with the rise of technological advancements in general and continues to encompass a growing number of aspects in cultural, political, and economical life of modern society (Mohamed, et al, 2020). However, the variety of what is considered an AI tool is quite vast. For the purposes of this paper, we will use the definition of AI outlined by the Routledge Social Science Book of AI (Elliott, 2022). Broadly speaking, AI can refer to any computational system which can react to, respond to, and learn from its environment. Since the publication of Donna Haraway’s “Cyborg Manifesto” in 1984, anthropology scholars have taken several approaches to study and observe the relationships that humans form with technologies. In her TED talk “We are all Cyborgs Now,” Amber Case (2011) grapples with a traditional definition of cyborg, which is “an organism to which exogenous components have been added for the purpose of adapting to new environments.” Case discusses an important aspect that can be helpful for thinking about AI-enabled research and the relationships that are formed in that context. Technology, including computer technology, is first and foremost a tool. Humans have used tools for much of our history to extend the manifestation of the physical self. Tools have helped humans become faster, smarter, and allowed engagement with our environments in new ways. Kathleen Gibson (1991), among many other scholars, writes how tool use has influenced human evolution, and of the connections between tool making and tool use and various forms of cognition, language, and social organization. Tim Ingold (1991) discusses the use of tools and the connection to the way humans socialize and evolution of intelligence. He emphasized that a form of knowledge, or the technique for tool use is different from technology itself. “The former is tacit, agent, and as a repository of experience – has been drawn from the center to the periphery of the labor process. In other words, it has been a movement from the personal to the impersonal,” (Ingold, 1988). Following Ingold, the tool, or the AI algorithm in the context of this paper, and the skill of the researcher who is using the tool are independent of each other. We propose to think about this relationship as a network, where the AI is a tool or a collaborator, a partner even, rather than a part of the researcher’s physical being.
Actor-Network Theory is a logical tool for engaging with and examining the relationships created by using AI technologies (Latour, 2007) because it considers all entities of the network as actors, and examines a multitude of relations, power dynamics and transformations within these networks. Technology is moving at an incredible speed, and changes to the relationship between AI and researchers are inevitable but can be difficult to pinpoint. Additionally, Actor-Network Theory allows for the examination of the agency of each actor in the network, including the AI algorithm(s). In a Remesh conversation there are many interactions occurring, and the relationships are multifaceted. In a temporally defined community, the researcher is interacting with the participants, the observers, the AI, the maker engineers and maintainers, yielding a robust network that has varied power dynamics.
A Remesh conversation creates a temporally contained socio-technical ecosystem. The anthropological concept of a socio-technical system was described by Bryan Pfaffenberger (1992) in his work Social Anthropology of Technology. Pfaffenberger connects the study of technology and the study of material culture and explores the history of technology in human culture through a socio-technical lens, stemming from the work of Thomas Hughes on the rise of modern electrical power systems. “According to Hughes, those who seek to develop new technologies must concern themselves not only with techniques and artifacts; they must also engineer the social, economic, legal, scientific, and political context of the technology,” (Pfaffenberger, 1992). In this framework, a successful technological intervention is only possible through an interaction of all actors in the socio-technical system. Thinking of a Remesh conversation as an example of this socio-technical system allows for a closer look at that the interaction between the actors, and the relationships that this system can build.
Research into ML and AI uncovers several complex ethical, cultural, and legal issues. Advances in artificial intelligence and machine learning now allow AI-enabled platforms to autonomously execute tasks that had been previously performed by humans. For example, the competence of AI-enabled platforms in the realm of writing and art has been at the forefront of cultural debates recently (Anderson and Anderson, 2007; Allen et al., 2005; Boden, 2016; Boddington, 2017; Brynjolfsson and McAfee, 2016; Bostrom, 2016). AI is now rapidly developing, globally available, and used in its many iterations. However, as with other technological advancements, there is a concern that the rise of AI brings new risks for the future of jobs (Anderson and Anderson, 2005; Allen et al., 2006). As the prevalence of AI rises in peoples’ daily lives, fear and concern over its implication is one of the many ways the relationships between actors in the socio-cultural system around AI can manifest.
As researchers engage with AI, these social dimensions must be considered before deploying AI as a tool in our own work. For example, the Remesh platform engages participants through voting on other participants’ responses, and then calculates an agreement score. Because the platform is fully text-based, researchers must carefully structure questions to ensure clarity and ease of response, thus ensuring ease in voting. In the case of conversations with sensitive topics, the researcher may consider forgoing the voting exercise altogether to ensure participant privacy. As researchers continue to engage with platforms like Remesh to aid in qualitative research projects, it is beneficial to access training and gather new data on the ethical and social issues related to AI and continue to discuss useful approaches and observed changes.
Finally, when it comes to interacting with AI-enabled tools, there is not only the researcher’s perspective on AI but, inevitably, the interaction between the researchers and the engineers who build and maintain the AI algorithm. Diana Forsythe (2001) writes about the differences in which engineers and social scientists see the world, and the rifts that develop between disciplines because of that difference. Forsythe writes that social scientists and engineering professionals have an inherently different way of understanding knowledge. For ‘knowledge engineers’ the nature of knowledge is not problematic, thought of as an absolute, based on formal rules, and is a purely cognitive phenomenon. In contrast, social scientists think of knowledge in terms of its relationship to social and cultural contexts, with variations between right and wrong, and as a social and cultural phenomenon in addition to being a cognitive phenomenon (Forsythe, 2001). In this sense, the socio-technical ecosystem around AI incorporates many actors, including the humans who built the algorithm.
As ethnographers, to truly understand and successfully employ AI technology, we must strive to understand the makers of AI algorithms and the way they think about knowledge through a social science approach.
BREAKFAST RITUALS AS AN ALGORITHMIC SPRINGBOARD
To explicate the socio-technical entanglements researchers experience when interacting with AI-enabled systems, the authors employed the Remesh platform to carry out a singular research study with 19 participants in a Remesh Flex asynchronous conversation. Since the subject of the conversation was not central to analysis, the authors opted for a light and engaging topic focused on breakfast rituals. As every person’s breakfast experience varies based on their preferences, family, culture, geography, and socioeconomic status, a conversation discussion guide was written to elicit a variety of agreement and disagreement interactions in a way that did not spark an ethical debate. Convenience sampling was selected as the sample recruitment strategy, with under the age of 18 being the sole terminating factor. Participants were asked their age, gender, to identify their favorite meal, how often they eat breakfast, and whether they were raised in the US or another country up to age 16 before the conversation began.
Once in the virtual ‘room’, participants were asked a series of Poll (quantitative) and Ask Opinion (qualitative open ended with participant voting) questions related to their early memories of breakfast, similarities between their breakfast preferences as a child and an adult, American breakfast habits through time, and were shown images of American breakfast in the 1800’s and 1900’s. Participants were asked to select which breakfast they would eat and why.
Six Ask Opinion questions generated a variety of robust responses, with some participants offering very rich answers and specific memories. From a researcher perspective, the data set was high-quality and would provide rich insight if ‘breakfast rituals’ were the lens of analysis. Each response was analyzed using the Remesh preference-inference algorithm and assigned a ‘percent agree’ score.
HOW REMESH USES MACHINE LEARNING: INFERENCING TO PREDICT PARTICIPANT BEHAVIOR
Remesh’s preference-inference algorithm processes participant responses semantically, mathematically representing the meaning of each response to identify how similar responses are to one another. Response similarity helps the algorithm more accurately predict utility scores. Each response is then passed through a Natural Language Processing (NLP) Term Frequency – Inverse Document Frequency algorithm to identify how often a term appears and estimate the importance of each term. Key to calculating the output of the algorithm is the preference voting process each participant experiences.
Of the four question types available on the platform, ‘Ask Opinion’ question responses are processed by the preference-inference and NLP algorithms. The moderator asks an open-ended Ask Opinion question, to which participants then respond to and submit their answer. After submitting their answer, participants are then prompted to vote during two exercises on other participants responses. First, participants are randomly presented with a single response and asked to agree or disagree with the response, repeating the process five times. This exercise gives the preference-inference algorithm an absolute baseline on what types of responses the participant agrees or disagrees with. Second, participants are shown two responses from other participants in a binary choice exercise. Participants are asked to select the response they prefer more, again repeating the process five times. This exercise gives the preference-inference algorithm a relative signal of agreement of responses, which are then sorted in order of agreement. The more times a participant votes (such as in additional Agree/Disagree or Binary Choice exercises) the more the algorithm learns about their preferences and does a better job at predicting voting behavior. The algorithm reflects its learning in two ways:
- In the Agree/Disagree exercise, participants indicate whether they agree or disagree with a randomly selected response. The algorithm records a (+1) for agree and a (-1) for disagree.
- In the Binary Choice exercise, participants select the response they agree with more. The algorithm learns the participants has a higher preference for that response and records a (+1).
Depending on the time left to complete the question in a Live session (all questions are timed), participants may repeat the voting exercises with new responses. In a Flex session (an asynchronous conversation option) questions are not timed but participants participate in the same voting exercises.
Up to 1,000 participants may participate in a Live Remesh conversation, and up to 5,000 in a Flex asynchronous conversation. As such, it would be impossible for every participant to vote on every response submitted to an Ask Opinion question in a timely manner. The preference-inference algorithm, however, will have collected enough participant voting behavior to infer how an individual participant would vote on a specific response and the algorithm works to fill in the blind spots. For example, suppose four participants are voting during a Remesh conversation. As seen in Figure 1, Participant 1 has voted on three responses and scores have been recorded. The participant agreed with Response 1, was neutral on Response 2, disagreed with Response 3, and did not vote on Response 4. The voting behaviors of the other three participants were also recorded.

Problematically, there is data missing in Figure 1 – all participants failed to vote on at least one response, leaving gaps in the grid. The preference-inference algorithm, having learned participants’ preference behavior, can now infer how they would most likely vote on responses with missing data. Participants 2 and 4 voted similarly on Responses 3 and 4, and therefore the algorithm will infer these participants would vote similarly on similar responses and fills in the blanks. Since the algorithm can’t know exactly how a participant will vote, it is programmed to ‘hedge its bets’ and completes blank spaces in the grid with smaller values (see Figure 2).

Once the algorithm has learned participant voting behavior it can produce outputs, which the preference-inference algorithm calculates as a ‘percent agree’ score. This value is calculated by counting the number of participants with a positive preference for the response and divided by N (see Figure 3).
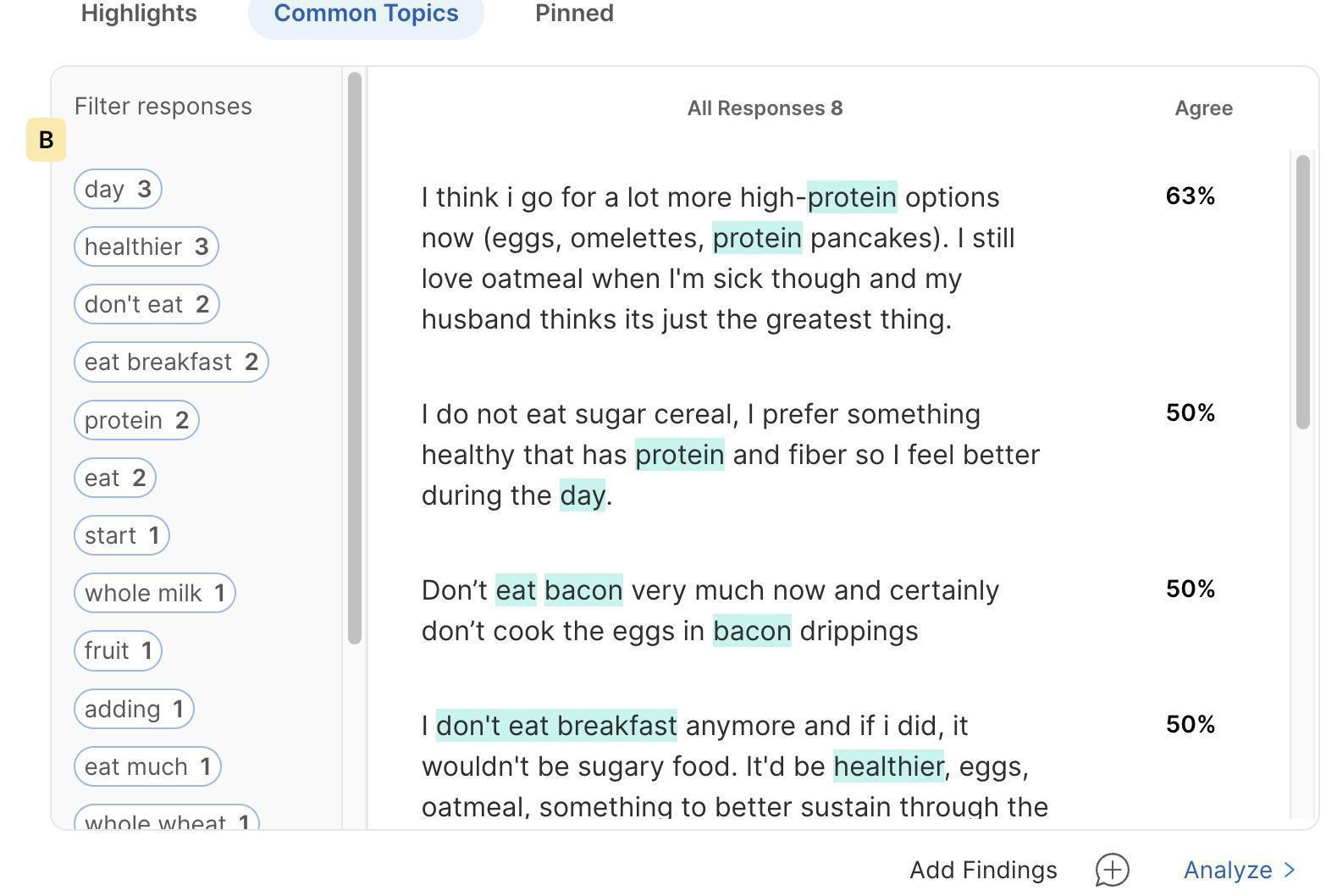
Participants were asked the following question: “In what ways are your current breakfast choices different than your child/teen breakfast choices? Why are they different? Please describe.” After typing and submitting their own response, participants voted in the Agree/Disagree and Binary Choice exercises. The preference-inference algorithm then assigned percent agree scores to every response, as seen in Figure 3. The top agreed response ‘I think I go for a lot more high protein options now…’ was scored at 63%, meaning 63% of participants are predicted to agree with this statement. Do 63% of participants absolutely agree? The researcher, and the algorithm, cannot make that claim because every participant does not vote on every response. But if participants vote truthfully, the preference-inference algorithm will make its best prediction based on their voting behavior and the researcher can be confident the scores are an accurate prediction.
Algorithms and Qualitative Research
Where ethnographers and algorithms intersect is in the search for patterns (Munk, et al, 2022). The path to elucidating patterns, and the output generated because of these patterns, may be wildly different – with the ethnographer leaning toward fieldwork and thick description in the form of language and the algorithm relying on large data sets of 1’s and 0’s to perform calculations and create numerical outputs. The ethnographer, however, is typically trained in self-reflexivity and understands the importance of situating themselves as an element in the research process, but the algorithm has no such self-awareness and is often – inappropriately – positioned as neutral or culturally agnostic because it is solidly situated in computation. Algorithms, like any other man-made construction, are encoded with social values (Elish & boyd, 2018). Imbued in late capitalism’s value of hard work – the coding, problem solving, cleaning, curating, debugging, testing, and training the engineers have performed in creating and maintaining the algorithm (Elish & boyd, 2018) – the speed, efficiency and trueness of the algorithmic output confirms the hard work. The ethnographer, situated at a distance from the algorithm’s makers and maintainers, and removed from the ‘work’ of the algorithm itself (the opacity of algorithms and the pace at which they operate can cause consternation as the work is occurring ‘in the machine’), is entangled in hard work regardless how seamlessly the output is generated, and regardless of their own personal perspective on algorithmic ‘work’. As a beneficiary of its output, the ethnographer must reckon with this layered positionality in addition to their own self-reflexivity in the research process. Particularly as it relates to value, an ethnographer is especially susceptible to discounting hard work in this context because of their distance from the makers and maintainers.
TOWARD A MODEL OF RESEARCHER-AI INTERACTION
As AI usage in qualitative research is in early and tenuous stages of relationship development, the authors have sketched a nascent model of researcher-AI interaction informed by Actor-Network Theory and designed around the specific interactions observed in a Remesh conversation (see Figure 4). This proposed model is situational and will most likely require modification for other AI-enabled research tools, but what should hold true is how researchers and engineers (both makers and maintainers) interact with algorithms or an algorithm.
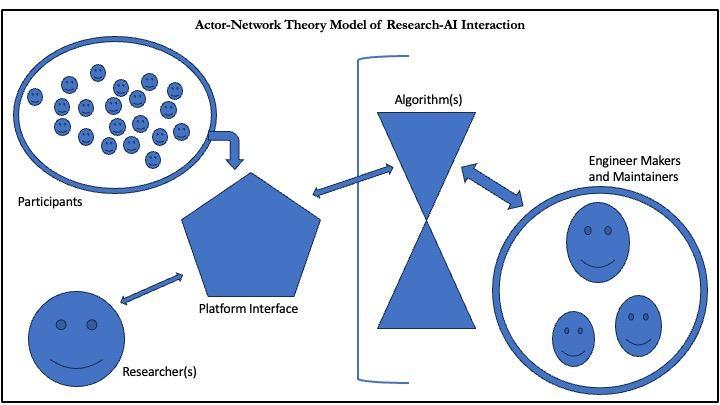
A researcher (single smiley face on the left) will never directly interact with an algorithm and will experience the algorithm as a set or sets of outputs delivered via a platform interface (represented by the pentagon). Participants (group of smiley faces on the left) will enter their data into the platform interface to be processed by the algorithm but never interact with it directly. The bracket indicates the opacity researchers and participants experience – they have no ‘view’ into the algorithm. Makers or maintainers (group of smiley faces on the right) will interact directly with the algorithm because they must work to code or program the platform where the algorithm lives and does its work. Makers and maintainers are not bounded by a bracket because they have a closer ‘view’ into the algorithm, as they program the algorithm directly if there are updates or changes that need to be made.
Additionally, it is important to note this model is a snapshot in time but does not represent the full variety of scenarios that might be at play. As discussed earlier, this collaborative process is happening across time and space. Researchers, participants and makers/maintainers may be interacting with the algorithm simultaneous or entirely asynchronously. Since the algorithm lives in a data cloud, access is flexible. Makers and maintainers typically interact with the algorithm in the course of their daily tasks, commonly during regular working hours. Researchers and participants will only interact with the algorithm during specific data collection periods, when participant responses are analyzed shortly after submission. Data collection could coincide with makers/maintainers working hours; it might not.
To be sure, this model requires further explication of the human and non-human actors as well as the concepts, ideas, and factors related to the actors in the network. The authors plan additional research and theorizing of this relationship map and invite the qualitative research community to contribute to building this model.
DISCUSSION
Ethnographers have a historically tense relationship with new technologies. As Forsythe (2001) points out, ethnographers have a different way of thinking about the world and can be reluctant to embrace technological change for fear of being labeled deterministic. Thinking of AI as a partner and a collaborator in the research process can help break that barrier and encourage the community to become more knowledgeable about AI. It is not necessary to become an engineer, but embracing the possibilities of AI in research would be a critical first step, along with learning about how the technology functions and the hard work expended in their creation. Understanding the worldview of engineers who create and work with AI can also become a way to break down barriers. As qualitative researchers, we can pave the way to closer relationships between our disciplines by studying the engineer’s experience and gain an informed point of view. We suggest the next step is to explore and understand the barriers for ethnographers to use AI and technology in general. We talk about technology and tools as a discipline but are rarely comfortable with them in practice. As noted by Zafirolu and Chang (2018), ethnographers may bear the responsibility toward engaging with technology as today’s society is heavily oriented towards big data and positivistic ways of thinking. This focus holds true for the approach Remesh takes in how it problematizes qualitative data, and ‘solving’ this problem with numeracy. In applying AI to qualitative data, the implied problem is that qual is not quant. As ethnographers, we know qual is not quant for a very good reason – qualitative data offers insights centered on ‘how’ and ‘why,’ versus the ‘what’ and ‘how many’ of quantitative. The function of every algorithm is mathematical, whether it’s preference-inference ML calculating a percent agreement score at the speed of light, or a large language model like ChatGPT tokenizing words so that it can respond to a prompt. Even as the ethnographic community has positioned its way of thinking as critical to understanding the world and an important strategic partner for solving sticky problems, the tidal wave of AI is unavoidable. Ethnographers now and in the future, to have any semblance of control over AI-enabled qualitative data analysis, must gain familiarity with how algorithms are constructed, their behaviors, and their limitations, as well as an in-depth understanding of the engineers involved in the creation, deployment and upkeep of algorithms. This expert knowledge can become a critical tool in the ethnographer’s toolkit, allowing for deeply contextualized and insightful interpretation of AI outputs, and affording new consideration of self-reflexivity in socio-technical entanglements. As the community gains deeper knowledge, how and in what ways we value the hard work of AI can be based on the realities that actually exist versus sensationalized fantasies driven by fear of the other.
Finally, it is important for researchers to embrace AI-enabled tools as partners, not adversaries. To do this, ethnographers must carefully examine the roles of each of the actors in the network. A successful collaboration between a researcher and AI exhibits clearly defined roles and expectations, based on new data about various interactions of researchers and AI. As part of this partnership, we must be careful as to not replicate the excusing power hierarchies in our society. Forsythe (2001) writes of the erasure of women in informatics, and this can be applied to other marginalized groups as well. As we engage with these tools, it is critical to ensure the stories and experiences of all groups are present in the narrative, and that any biases that exist within the algorithm adjusts to not only represent but also critique inequities in current society.
CONCLUSION
As the prevalence of AI-enabled research platforms in the qualitative research industry increase, researchers must be mindful of the socio-cultural engagements and the relationships formed and transformed through these entanglements. As practitioners of the social sciences, we must engage critically but also introspectively with all aspects of AI technology, including other users and makers. It is important to these new technologies as one of the tools available to us, and treat the work done with AI in a collaborative manner, but keeping in mind the exact roles that each actor performs in the collaboration. The proposed model is a starting point for acknowledging the hard work of all actors involved in data analysis, and an invitation to explicate the importance of valuing each other’s hard work.
ABOUT THE AUTHORS
Suzanne Walsh is an anthropologist with expertise in business and health research. With over 25 years of experience in academia and consulting, she currently works at Remesh, a SaaS AI-enabled research platform, as a Research Consultant. Suzanne helps clients puzzle through sticky employee and organization research problems, and leverages machine learning, NLP and GPT to understand qualitative data at scale. She has published in high-impact journals, and authors thought leadership for Remesh. s.walsh@remesh.org
https://www.linkedin.com/in/svwalsh/
Jara Pallas-Brink is a cultural anthropologist with 15 years of experience in ethnographic research. While her primary area of study is food access and community resilience, she has a wide range of interdisciplinary experience in academia and research consulting. Currently, she is a Qualitative Research Manager at Human8, a global consultancy that connects brands with people and culture. Jara uses her skills as an ethnographer to help clients think through challenges and complex problems.
https://www.linkedin.com/in/jara-pallas-brink-14a27753/
REFERENCES
Albris, K., Otto, E.I., Astrupgaard, S.L., Munch Gregersen, E., Skousgaard, L., Jørgensen, O., Sandbye, C. R., Schønning, S. (2021). A view from anthropology: Should anthropologists fear the data machines?. Big Data & Society July–December: 1–7.
Allen, Colin, Wendell Wallach, and Iva Smit. “Why machine ethics?.” IEEE Intelligent Systems 21, no. 4 (2006): 12-17.
Amoore, L. (2019). Doubt and the algorithm: On the partial accounts of machine learning. Theory, culture society., 36 (6). pp. 147-169.
Anderson, Michael, and Susan Leigh Anderson. “Machine ethics: Creating an ethical intelligent agent.” AI magazine 28, no. 4 (2007): 15-15.
Bang, Seung Ho (2014). Thinking of artificial intelligence cyborgization with a biblical perspective (anthropology of the old testament). European Journal of Science and Theology, June 2014, Vol.10, No.3, 15-26.
Becker, J. (2022). The Three Problems of Robots and AI.” Social Epistemology Review and Reply Collective 11 (5): 44-49.
Beckwith, R., Sherry, J. (2020). Scale and the Gaze of a Machine. 2020 EPIC Proceedings pp. 48–60, ISSN 1559-8918, https://www.epicpeople.org/scale-gaze-machine/.
Bjerre-Nielsen, A., Lind Glavind, K. (2022). Ethnographic data in the age of big data: How to compare and combine. Big Data & Society January–June: 1–6.
Brynjolfsson, Erik, and Andrew McAfee. Race against the machine: How the digital revolution is accelerating innovation, driving productivity, and irreversibly transforming employment and the economy. Brynjolfsson and McAfee, 2011.
Brin, D. (2022). Essential (mostly neglected) questions and answers about artificial intelligence. Neohelicon (2022) 49:429–449.
Boden, Margaret A. AI: Its nature and future. Oxford University Press, 2016.
Boddington, Paula. Towards a code of ethics for artificial intelligence. Cham: Springer, 2017.
Borch, C., & Hee Min, B. (2022). Toward a sociology of machine learning explainability: Human–machine interaction in deep neural network-based automated trading. Big Data & Society, 9(2).
Case, Amber. Calm technology: principles and patterns for non-intrusive design. ” O’Reilly Media, Inc.”, 2015.
Cemaloglu, C., Chia, J., Tam, J. (2019). Agency and AI in Consulting Pathways to Prioritize Agency-Enhancing Automations. 2019 EPIC Proceedings pp 533–553, ISSN 1559-8918, https://www.epicpeople.org/agency-ai-consulting-pathways-prioritize-agency-enhancing-automations/.
Chablo Source, A. (1996). What Can Artificial Intelligence Do for Anthropology?. Current Anthropology, Jun., 1996, Vol. 37, No. 3 (Jun., 1996), pp. 553-555.
Cibralic, B., Mattingly, J. (2022). Machine agency and representation. AI & SOCIETY.
Ciechanowskia, L., Jemielniaka, D., Gloorb, P.A. (2020). AI Research without Coding. Journal of Business Research 117, 322–330.
Dafoe, Allan. “On Technological Determinism: A Typology, Scope Conditions, and a Mechanism.” Science, Technology, & Human Values 40, no. 6 (2015): 1047–76. http://www.jstor.org/stable/43671266.
Dahlin, E. (2022). Think Differently We Must! An AI Manifesto for the Future. AI & SOCIETY.
Danziger, E. (2022). Anthropology, AI and The Future of Human Society : RAI, London, 6-10 June 2022. Anthropology Today, 38 (5).
Davis, F. (1989) Perceived Usefulness, Perceived Ease of Use, and User Acceptance of Information Technology. MIS Quarterly, 13, 319-340.
Dennis, L. (2020). Computational Goals, Values and Decision-Making. Science and Engineering Ethics, 26:2487–2495.
Dignum, Virginia. “Ethics in artificial intelligence: introduction to the special issue.” Ethics and Information Technology 20, no. 1 (2018): 1-3.
Elish, M.C. (2018). The Stakes of Uncertainty: Developing and Integrating Machine Learning in Clinical Care. 2018 EPIC Proceedings, ISSN 1559-8918, https://www.epicpeople.org/machine-learning-clinical-care/.
Elish, M.C. & boyd, d. (2018) Situating methods in the magic of Big Data
and AI, Communication Monographs, 85:1, 57-80, DOI: 10.1080/03637751.2017.1375130.
Elliott, A. (Ed.). (2021). The Routledge Social Science Handbook of AI (1st ed.). Routledge. https://doi.org/10.4324/9780429198533
Forsythe, D. (1993). The Construction of Work in Artificial Intelligence. Science, Technology, & Human Values, Vol. 18, No. 4 (Autumn), pp. 460-479.
George, A., & Walsh, T. (2022). Artificial intelligence is breaking patent law. Nature, 605(7911), 616-618.
Govia, L. (2020). Coproduction, ethics and artificial intelligence: a perspective from cultural anthropology. JOURNAL OF DIGITAL SOCIAL RESEARCH—VOL. 2, NO. 3.
Gibson, Kathleen R., Kathleen Rita Gibson, and Tim Ingold, eds. Tools, language and cognition in human evolution. Cambridge University Press, 1993.
Guo, T. (2015). Alan Turing: Artificial intelligence as human self-knowledge. ANTHROPOLOGY TODAY VOL 31 NO 6, DECEMBER 2015
Harmon, P., King, D. (1985) Experts systems: Artificial intelligence in business. Wiley; 1st edition (April 4).
Hauer, T. (2022). Importance and limitations of AI ethics in contemporary society. HUMANITIES AND SOCIAL SCIENCES COMMUNICATIONS, 9:272.
Hayes-Roth, F., Waterman, D.A., Lenat D.B. (1983) Building expert systems. Addison-Wesley, London.
Hemotology/Oncology Today (2019). AI an emerging tool, not substitute, for oncologists., AUGUST 25, VOL. 20 NO. 16.
Ingold, Tim. “Tools, minds and machines: an excursion in the philosophy of technology.” Techniques & culture (Paris) 12 (1988): 151-178.
Jorian, P. (2022). Humanism and its Discontents: The Rise of Transhumanism and Posthumanism. Palgrave Macmillan; 1st ed.
Latour, Bruno. (2007) Reassembling the social: An introduction to actor-network-theory. Oup Oxford, 2007.
Laughlin, C.D. (1997). The Evolution of Cyborg Consciousness. Anthropology of Consciousness 8(4):144-159.
Lyon, S., Fischer, M. (2006). Anthropology and Displacement: Culture, Communication and Computers Applied to a Real World Problem. Anthropology in Action, 13, 3 (2006): 40–53.
Magee, L., Arora, V., Munn, L. (2022). Structured Like a Language Model: Analysing AI as an Automated Subject. arXiv preprint arXiv:2212.05058, 2022 – arxiv.org
Maiers, C. (2018). Reading the Tea Leaves: Ethnographic Prediction as Evidence. 2018 EPIC Proceedings, ISSN 1559-8918, https://www.epicpeople.org/ethnographic-prediction-evidence/
Mariani, M.M, Perez-Vega, R. Wirtz, J. (2022). AI in marketing, consumer research and psychology: A systematic literature review and research agenda. Psychology and Marketing, 39:755–776.
Mohamed, S., Png, M-T., Isaac, W. (2020). Decolonial AI: Decolonial Theory as Sociotechnical Foresight in Artificial Intelligence. Philosophy & Technology (2020) 33:659–684
Moor, James. “The Dartmouth College artificial intelligence conference: The next fifty years.” Ai Magazine 27, no. 4 (2006): 87-87.
Müller, Vincent C., and Nick Bostrom. “Future progress in artificial intelligence: A survey of expert opinion.” Fundamental issues of artificial intelligence (2016): 555-572.
Munk, A.K., Olesen, A.G., Jacomu, M. (2022). The Thick Machine: Anthropological AI between explanation and explication. Big Data & Society January–June: 1–14.
Munn, L. (2022). The uselessness of AI ethics. AI Ethics. https://doi.org/10.1007/s43681-022-00209-w
Overgoor, G., Chica, M., Rand, W., Weishampel, A. (2019) Letting the Computers Take Over: Using AI to Solve Marketing Problems. California Management Review, Vol. 61(4) 156–185.
Paff, S. (2018). Anthropology by Data Science: The EPIC Project with Indicia Consulting as an Exploratory Case Study. ANNALS OF ANTHROPOLOGICAL PRACTICE, Vol. 46, No. 1, pp. 7–18.
Persson, A., Laaksoharju, M., Koga, H. (2021). We Mostly Think Alike: Individual Differences in Attitude Towards AI in Sweden and Japan. The Review of Socionetwork Strategies (2021) 15:123–142
Pfaffenberger, Bryan. “Social Anthropology of Technology.” Annual Review of Anthropology, vol. 21, 1992, pp. 491–516. JSTOR, http://www.jstor.org/stable/2155997. Accessed 16 July 2023.
Sampson, O. (2018). Just Add Water: Lessons Learned from Mixing Data Science and Design Research Methods to Improve Customer Service. 2018 EPIC Proceedings, ISSN 1559-8918, https://www.epicpeople.org/just-add-water-lessons-learned-from-mixing-data-science-and-design-research-methods-to-improve-customer-service/.
Sapignoli, M. (2021). The mismeasure of the human: Big data and the ‘AI turn’ in global governance. ANTHROPOLOGY TODAY VOL 37 NO 1, FEBRUARY.
Sappington, R., Serksnyte, L. (2018). Who and What Drives Algorithm Development: Ethnographic Study of AI Start-up Organizational Formation. 2018 EPIC Proceedings, ISSN 1559-8918, https://www.epicpeople.org/algorithm-development/
Schneider, B. (2022). Multilingualism and AI: The Regimentation of Language in the Age of Digital Capitalism. Signs and Society, volume 10, number 3, fall.
Samuel, G., Diedericks, H., Derrick, G. (2021). Population health AI researchers’ perceptions of the public portrayal of AI: A pilot study. Public Understanding of Science, Vol. 30(2) 196–211
Sartori, L., Theodorou, A. (2022). A sociotechnical perspective for the future of AI: narratives, inequalities, and human control. Ethics and Information Technology, 24:4.
Scott, A.C., Clayton, J.E., Gibson, E.L. (1991). A Practical Guide to Knowledge Acquisition. Addison-Wesley Publishing Company.
Sebastian, M. A., Rudy-Hiller, F. (2021). First-person representations and responsible agency in AI. Synthese, 199:7061–7079.
Singler, Beth. “Artificial Intelligence and the.” AI Narratives: A History of Imaginative Thinking about Intelligent Machines (2020): 260.
Su, Z., Togay, G., Côté, A-M. (2021). Artificial intelligence: a destructive and yet creative force in the skilled labour market. HUMAN RESOURCE DEVELOPMENT INTERNATIONAL, VOL. 24, NO. 3, 341–352
Thurzo, A., Svobodová Kosnácová, H., Kurilová, V., Benuš, R., Moravanský, N., Kovác, P., Mikuš Kuracinová, K., Palkovi, M., Varga, I. (2021). Use of Advanced Artificial Intelligence in Forensic Medicine, Forensic Anthropology and Clinical Anatomy. Healthcare, 9, 1545.
Walker Rettberg, J. (2022). Algorithmic failure as a humanities methodology: Machine learning’s mispredictions identify rich cases for qualitative analysis. Big Data & Society July–December: 1–6.
White, D., Katsuno, H. (2021). TOWARD AN AFFECTIVE SENSE OF LIFE: Artificial Intelligence, Animacy, and Amusement at a Robot Pet Memorial Service in Japan. CULTURAL ANTHROPOLOGY, Vol. 36, Issue 2, pp. 222–251.
Yolgormez, C., Thibodeau, J. (2022). Socially robotic: making useless machines. AI & SOCIETY, 37:565–578.
Yu, R., Ali, G.S. (2019). What’s Inside the Black Box? AI Challenges for Lawyers and Researchers. Legal Information Management, 19, pp. 2–13.
Zafiroglu, A., Chang, Y-N. (2018). Scale, Nuance, and New Expectations in Ethnographic Observation and Sensemaking. 2018 EPIC Proceedings, ISSN 1559-8918, https://www.epicpeople.org/scale-nuance-expectations-in-ethnographic-observation-sensemaking/.
